ICML 2026
Trust Functions: Near-Lossless Weak-to-Strong Generalization by Learning When to Trust the Weak Teacher
TLDR: Learning-to-Trust identifies which weak labels are reliable enough to supervise stronger students, recovering near ground-truth performance through trust-filtered weak supervision.
Approach
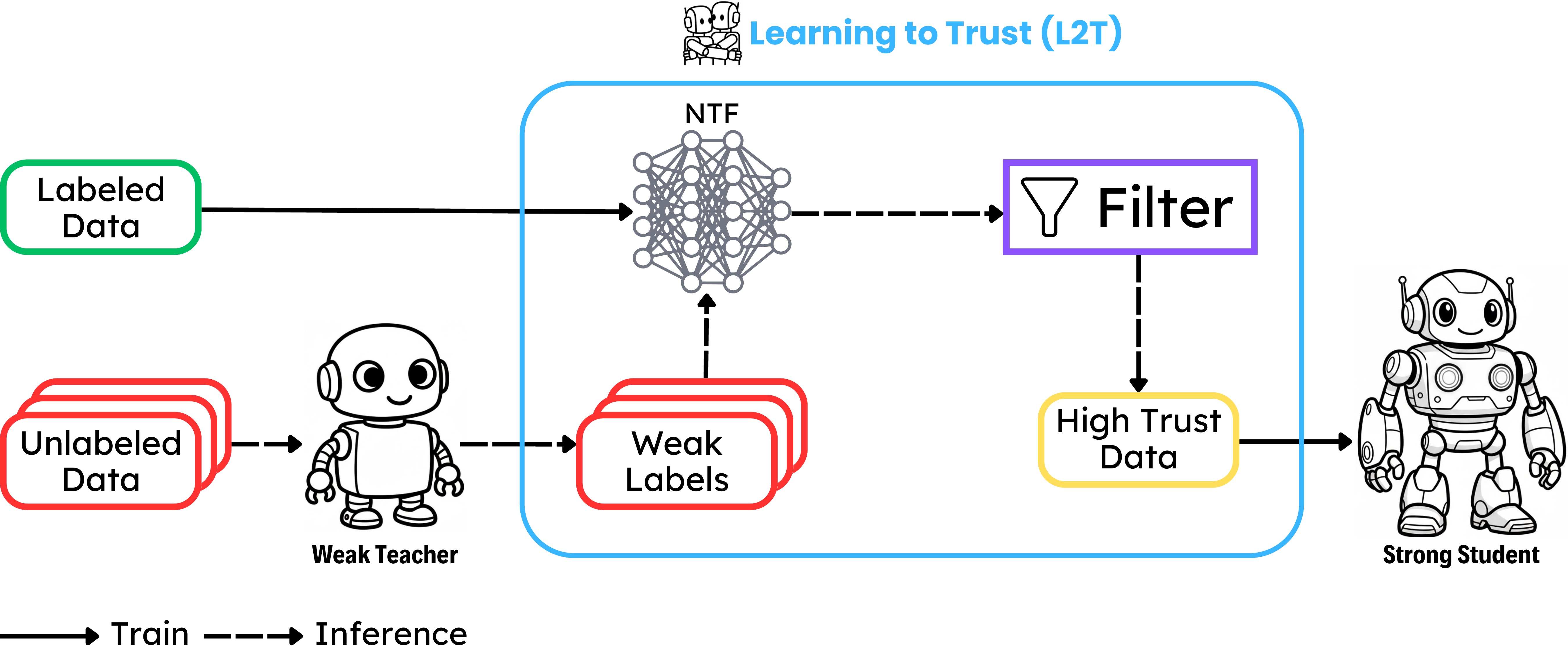
Our method treats weak-to-strong generalization primarily as a data selection problem. Rather than training a strong student on all weak labels equally, we introduce a trust function that assigns each weak label a scalar trust score reflecting its estimated reliability as supervision. In our instantiation, this trust function is a neural network that is trained on a labeled source distribution to predict whether a weak teacher’s output is correct from the teacher’s hidden states.
At deployment, the weak teacher generates labels on unlabeled target data, the neural trust function scores those labels, and only the highest-trust examples are retained for student training. This yields a filtered supervision set that preserves the benefit of weak labels while reducing harmful or misleading ones. Crucially, the same trust-filtering procedure can be applied iteratively: once a student is trained, it can be reused as the next teacher, producing a weak-to-strong chain that compounds gains across generations and often approaches ground-truth supervision with little loss.
Results
World Knowledge
OBQA, ARC-C, ARC-E, SciQ, and SIQA
| Method | OLMo2-1B | OLMo2-7B | OLMo2-13B | Qwen3-0.6B | Qwen3-1.7B | Qwen3-4B | Qwen3-8B | Qwen3-14B |
|---|---|---|---|---|---|---|---|---|
| Teacher Performance | 43.1 | 52.6 | ||||||
| No-SFT | 43.1 | 65.1 | 73.8 | 52.6 | 69.1 | 72.0 | 77.3 | 79.4 |
| Naive | 49.0 | 69.3 | 74.7 | 59.2 | 74.0 | 78.5 | 83.8 | 86.0 |
| I-Confidence | 49.2 | 69.2 | 75.1 | 59.4 | 74.3 | 78.8 | 83.8 | 85.7 |
| ICL + I-Confidence | 50.0 | 72.0 | 77.9 | 61.8 | 74.4 | 79.4 | 84.8 | 86.5 |
| Ensemble | 49.2 | 70.9 | 76.7 | 59.7 | 74.1 | 77.2 | 82.9 | 85.1 |
| RM | 46.1 | 68.9 | 78.4 | 59.0 | 71.7 | 77.0 | 82.6 | 86.1 |
| NTF (Ours) | 50.5 | 73.7 | 80.9 | 61.6 | 75.0 | 80.0 | 84.9 | 87.1 |
| Ground Truth | 49.6 | 73.8 | 81.2 | 61.9 | 74.8 | 80.6 | 85.2 | 87.0 |
| Recovery (%) | 113.9 | 98.9 | 95.9 | 96.8 | 103.5 | 93.0 | 96.2 | 101.3 |
Dark green: super-recovery. Light green: near-lossless. Red: GT better.
Quantitative Reasoning
AIME
| Method | Qwen3-4B | Qwen3-8B | Qwen3-8B | Qwen3-8B |
|---|---|---|---|---|
| Teacher Performance | 4.27 | 4.27 | 10.91 | 18.88 |
| No-GRPO | 10.9 | 18.9 | 18.9 | 18.9 |
| Naive | 19.6 | 26.0 | 27.2 | 26.8 |
| I-Confidence | 20.7 | 25.6 | 26.7 | 27.3 |
| V-Confidence | 18.7 | 25.9 | 27.1 | 26.5 |
| NTF (Ours) | 22.0 | 26.6 | 27.9 | 27.4 |
| Ground Truth | 22.9 | 27.4 | 28.7 | 28.4 |
| Recovery (%) | 92.5 | 91.0 | 91.7 | 89.2 |
Decision Making
Lichess Puzzles
| Method | OLMo2-1B | OLMo2-7B | OLMo2-13B | Qwen3-0.6B | Qwen3-1.7B | Qwen3-4B | Qwen3-8B | Qwen3-14B |
|---|---|---|---|---|---|---|---|---|
| Teacher Performance | 28.5 | 6.9 | ||||||
| Naive | 34.7 | 37.0 | 38.3 | 10.6 | 22.1 | 27.0 | 33.7 | 38.1 |
| I-Confidence | 37.1 | 39.9 | 40.7 | 11.5 | 23.0 | 36.9 | 36.3 | 37.5 |
| V-Confidence | 35.2 | 37.7 | 38.7 | 7.3 | 17.9 | 31.8 | 31.8 | 33.4 |
| NTF (Ours) | 37.4 | 41.2 | 41.5 | 15.5 | 25.4 | 35.4 | 38.0 | 44.1 |
| Ground Truth | 37.7 | 52.9 | 54.5 | 14.9 | 23.0 | 36.3 | 37.0 | 39.9 |
| Recovery (%) | 99.2 | 77.9 | 76.1 | 104.4 | 110.5 | 97.6 | 102.9 | 110.4 |
Mechanisms
Easy-First Curriculum
NTF shifts selection toward easier puzzles, acting like an implicit curriculum.
Optimal Alternatives
Some labels marked incorrect are still strong alternatives under engine evaluation.
Coherent Gradients
Selected examples create more aligned, lower-rank update directions.
Finding 1 tests whether NTF's advantage can be explained simply by a curriculum effect. By comparing NTF to a difficulty-matched naive baseline, the table isolates how much of the gain comes from selecting easier examples versus from trust-based filtering itself.
Finding 1
Difficulty-matched ablation
| Method | Qwen3-1.7B | Qwen3-4B | Qwen3-8B | Qwen3-14B |
|---|---|---|---|---|
| NTF (Ours) | 25.4 | 35.4 | 38.0 | 44.1 |
| Naive | 22.1 | 27.0 | 33.7 | 38.1 |
| Naive-DM | 24.8 | 29.7 | 32.7 | 35.9 |
Finding 2 asks whether NTF works only because it selects better training examples, or also because some labels marked incorrect by the dataset are still strong alternatives. Replacing NTF-selected teacher labels with ground truth helps separate the value of selection from the value of retaining these alternative labels.
Finding 2
Ground-truth relabeling on the NTF subset
| Method | Qwen3-1.7B | Qwen3-4B | Qwen3-8B | Qwen3-14B |
|---|---|---|---|---|
| Ground Truth | 23.0 | 36.3 | 37.0 | 39.9 |
| NTF (Ours) | 25.4 | 35.4 | 38.0 | 44.1 |
| NTF-GT | 24.8 | 35.3 | 36.2 | 43.6 |
BibTeX
@misc{uzunoglu2026trustfunctionsnearlosslessweaktostrong,
title={Trust Functions: Near-Lossless Weak-to-Strong Generalization by Learning When to Trust the Weak Teacher},
author={Arda Uzunoglu and Alvin Zhang and Daniel Khashabi},
year={2026},
eprint={2606.01000},
archivePrefix={arXiv},
primaryClass={cs.LG},
url={https://arxiv.org/abs/2606.01000},
}